Tech-Talk: Fuzzing
In diesem Tech-Talk gab Luc Heitz eine Einführung in Fuzzing – einer Methode um automatisiert Software auf Schwachstellen zu untersuchen. Er begann mit einer amüsanten Analogie:

Fuzzing ist eine automatische Methode, um Software auf Schwachstellen zu untersuchen, indem die Software wiederholt mit zufällig generierten Eingaben ausgeführt wird und dann geprüft wird, ob die Software crasht oder in einer Schleife hängen bleibt.
Die Idee ist, dass durch millionenfache Ausführung eines Programms mit zufällig generierten Inputs Ausführungspfade begangen werden, die mit Unittests nicht gefunden werden. Ziel ist eine möglichst hohe Abdeckung aller Ausführungspfade, um auch jene Fehler zu finden, die in unvorhergesehenen Situationen auftreten.
Durch die zufällige Generierung der Inputdaten und einem limitieren Zeitbudget kann jedoch nicht garantiert werden, dass tatsächlich alle Pfade ausgeführt wurden.
Der Fuzzing-Ansatz kann in drei Kategorien unterteilt werden:
- Blackbox Fuzzing wird auch blindes Fuzzing genannt. Dabei hat der Fuzzer keine Einsicht in die getestete Software.
- Whitebox Fuzzing hingegen nutzt zusätzliche Programmanalysen wie z.B. Symbolic Execution, um den Generator der Inputdaten zu lenken.
- Greybox Fuzzing bewegt sich irgendwo dazwischen und verwendet leichtgewichtige Analysen, um eine Coverage Map zu erstellen und den Fuzzer auf bisher unbegangene Wege zu lenken.
Mit Fuzzing können Probleme gefunden werden, aber in der Regel nicht deren Abwesenheit bewiesen werden.
Fuzzing ist sehr vielseitig – der Ansatz funktioniert für interpretierte Sprachen, aber auch auf Maschinencode. Dabei kommen auch Hardware-Emulatoren (z.B. QEMU) zum Einsatz. Diese ermöglichen es, die Ausführung eines Programms zu instrumentieren und zu überwachen. Zudem ist es viel praktischer, auf einem Emulator die Komponenten eines Betriebssystems zu fuzzen – ein illegaler Speicherzugriff würde direkt das Hostsystem zum Absturz bringen.
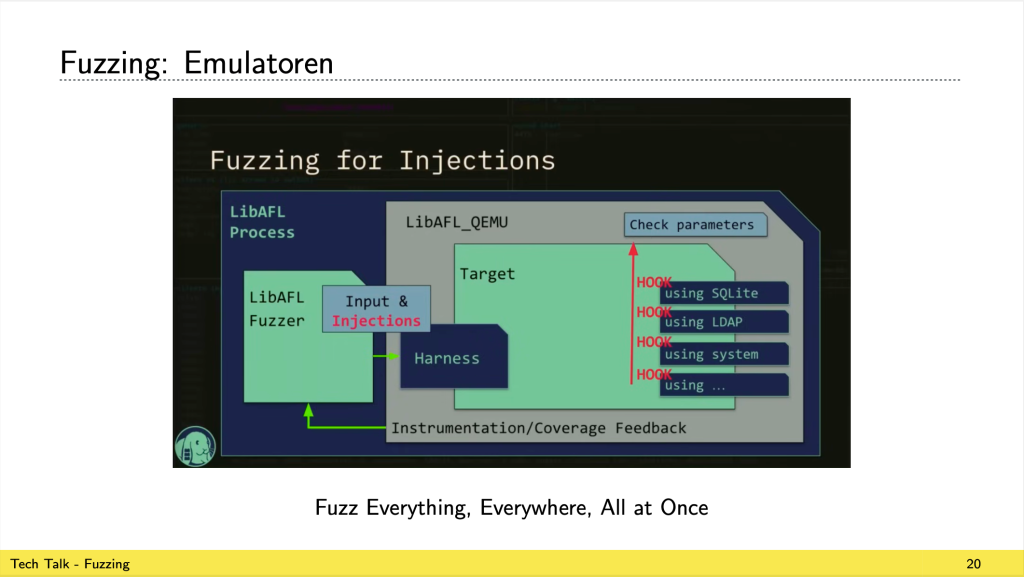
Durch reinen Zufall ist es sehr schwierig, Inputs zu generieren, die tief in ein Programm «reinkommen». Wenn man z.B. eine JavaScript-Runtime fuzzen will und einfach zufällige Strings erzeugt, ist die Chance sehr gering, jemals durch die erste Phase, den Parser, zu kommen. Abhilfe schafft z.B. die grammatik-getriebene Generierung von Inputs. Dabei wird die Struktur der akzeptierten Daten dem Fuzzer zugänglich gemacht. Als besonders effektiv, um Programmiersprachen prozessierende Tools zu fuzzen, hat sich der Token-basierte Ansatz erwiesen, bei dem Sequenzen von legalen Tokens rearrangiert werden.
Ein weiterer Ansatz ist Mutation-Based Fuzzing. Dabei werden erfolgreiche Inputs, also jene, die eine gewisse Laufzeit im Programm erzeugen oder eine gewisse Coverage erreichen, leicht modifiziert oder mit anderen erfolgreichen Inputs gekreuzt, um potenziell bessere Nachkommen zu erhalten.
Natürlich wird im Zusammenhang mit KI viel aktive Forschung betrieben – so kann KI verwendet werden, um die Grammatik von vielversprechenden Inputs zu lernen.
Fuzzing lässt sich gut mit konventionellen Testmethoden ergänzen und kann automatisiert in CI/CD-Pipelines seinen Teil zur Qualitätssicherung beitragen.
Tech-Talk: Luc Heitz (luc.heitz@fhnw.ch), MSc ETHZ Student und Assistent am IMVS
Blog Beitrag: Daniel Kröni (daniel.kroeni@fhnw.ch), Wissenschaftlicher Mitarbeiter am IMVS
Kommentare
Keine Kommentare erfasst zu Tech-Talk: Fuzzing